

Kuidas orienteeruda andmeanalüütika maailmas: mõisted, andmete migratsioon ja ristkasutus
Tänapäeva tehnoloogiarikkas ärimaailmas on andmeanalüütika kriitilise tähtsusega, sest võimaldab organisatsioonil teha informeeritud otsuseid ning parandada seeläbi ettevõtte efektiivsust ja konkurentsivõimet.
Käesolevas artiklis teeme tutvust andmete migreerimisega seotud oluliste mõistete ja protsessidega, et aidata sul paremini orienteeruda andmeanalüütika põnevas maailmas.
Põhimõisted selgeks
Andmeait, andmeladu (data warehouse, DWH) – struktureeritud ja mingil kindlal eesmärgil kogutud andmete kogum ehk andmebaas(id). Seda peetakse organisatsiooni andmete keskseks repositooriumiks ehk andmehoidlaks.
Andmejärv (data lake) – töötlemata andmete (raw data) kogum, mida kasutatakse sageli masinõppes algallikana. See võib samuti sisaldada kogu organisatsiooni andmestikku, kuid erinevalt andmeaidast ei tarvitse see olla veel kindla eesmärgi täitmiseks kasutusele võetud.
Suurandmed (big data) – hõlmab väga erinevas formaadis ja mittestruktureeritud andmeid, nagu veebistatistika, sotsiaalmeedia, sensorid, tekstidokumendid, audio, video jt. Kui andmeaidast räägitakse pigem kui arhitektuurist, siis suurandmete puhul rohkem kui tehnoloogiast.
Andmevakk, andmemart (data mart) – andmeaida väike versioon, mida saab luua konkreetse ärivaldkonna jaoks, võimaldades spetsiifilisemat analüüsi.
Andmemudel, semantiline mudel (dataset) – äriliste mõistetega andmete kiht, mis asub andmeaida ja aruannete vahel ning on loodud spetsiifiliste aruandlusvajaduste (nt kasumiaruande) jaoks.
Data flow – andmete laadimise protsess, kus andmed transporditakse ühest asukohast teise. See protsess on hädavajalik andmete integreerimiseks ja säilitamiseks.
Masterdata – keskne andmekogu, mida kasutatakse siis, kui esmane info ei ole infosüsteemist kättesaadav. Näiteks, kui toote omahinna teavet ei ole mingis rakenduses, võib vastutav spetsialist selle info käsitsi ettevalmistatud vormil sisestada (Excelis, äpis vm) ja see integreeritakse andmeaita.
Lisaks individuaalsete andmete haldamisele kasutatakse masterdata mõistet ka laiemalt, kui on vaja siduda sama andmekogumit mitmest algallikast, näiteks ühe ettevõtte erinevate riikide filiaalide kliendiregistrit.
ELT (extract, load, transform) metoodika – protsess algab andmete kogumisega algallikast, kust vajaminev tõstetakse töötlemata kujul andmeaita. Seejärel andmete transformeerimise faasis täiendatakse andmeid või parandatakse vigu, et kindlustada andmete täpsus ja usaldusväärsus.
ELT järel seotakse andmed optimeeritud andmemudeliks ning esitatakse kasutajatele sobival ja arusaadaval kujul. Vanasti kasutatud ETL terminist erineb uuem metoodika selle poolest, et transformatsioone tehakse peale laadimist.

Andmeanalüütika teekond ehk kuidas suurest hulgast andmetest sünnib raport
Kimballi metoodika mudel illustreerib nn front-end ja back-end vahelisi seoseid, pakkudes visuaalset ülevaadet protsessist, kus algandmetest saavad aruanded ja otsustustugi ettevõttele äriotsuste tegemiseks. Protsess jaguneb kolmeks etapiks: andmete ettevalmistus (ELT), ärimudeli(te) kiht ning tulemuste esitlemine koos analüüsivõimalustega.
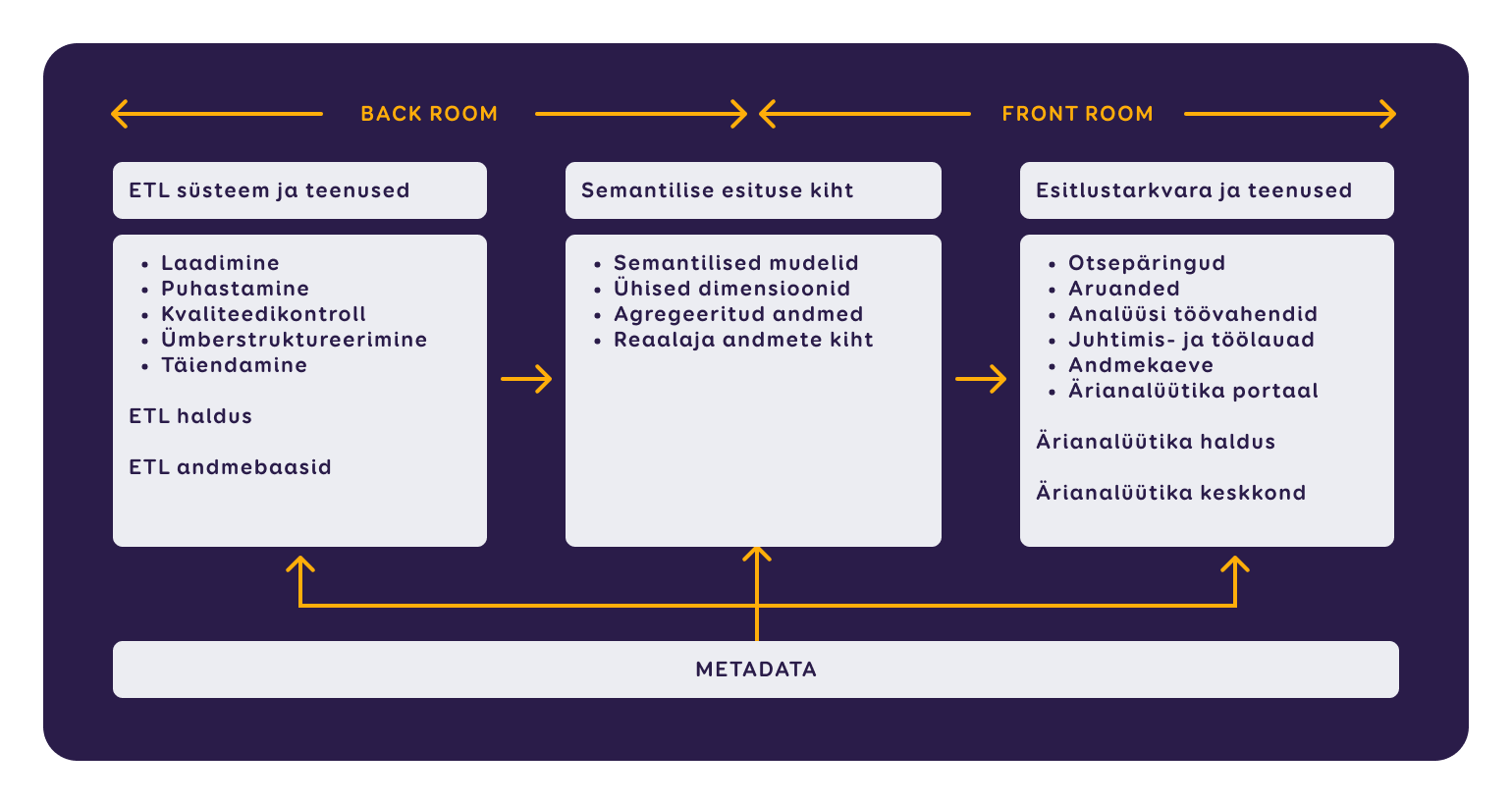
Selleks, et pakkuda efektiivseid BI (ärianalüütika) lahendusi, on meie sidusettevõte Intelex Insight välja töötanud andmearhitektuuri kujundamise standardid.
Need hõlmavad põhimõtteid, reegleid ja mudeleid, kuidas andmeid koguda, kirjeldavad kogutud andmete haldamist ja säilitamist, tagavad andmete konfidentsiaalsuse ja turvalisuse, annavad ülevaate aruandlusest ning loovad valmiduse andmete kasutajapoolseks analüüsiks.
Järgnevalt uurime lähemalt, kuidas sünnivad suurest hulgast algandmetest raportid ja BI lahendused sinu töölauale ehk mis toimub andmete ettevalmistuse tagaruumis.
ELT (extract, load, transform) ehk andmete kogumine, laadimine ja muutmine
ELT protsess hõlmab andmete kogumist algallikatest, nende laadimist andmeaita ning järgnevat andmete muutmist. Selleks on erinevaid võimalusi, sõltuvalt organisatsiooni spetsiifilisest poliitikast ja valitud tehnoloogilistest lahendustest.
Näiteks võib andmete töötlust teostada, kasutades Microsoft Visual Studio tarkvara, mida tänu oma visuaalsetele komponentidele võib nimetada isedokumenteeruvaks. Samas võib ainult programmeerides andmeid töödelda.
Ühesuguste algallikate puhul soovitame kasutada iteratiivset lahendust (nn loop). Suurema andmemahu korral veebiteenused väljastavad andmeid partiidena (näiteks 20 000 kirjet korraga), samuti on soovitav eraldi käsitleda muutunud andmete laadimist.
Milleks on vaja andmeaita/andmeladu (DWH´d)?
Andmeladu (Data Warehouse, DWH) on kriitilise tähtsusega komponent, mis aitab sul oma andmeid tõhusalt hallata ja analüüsida. Andmeait võimaldab…
- jälgida andmete muutusi ajas. Näiteks võimaldab see vaadata laoseisu muutusi päevade, kuude või kvartalite lõikes, luues nii andmete ajaloo, mida algallikast ei pruugi leida.
- hallata masterdata´t isegi kui see info puudub algallikates. Näiteks võib kasutada Excelit või Power Apps´i laadset äppi lisaandmete sisestamiseks, mis siis salvestuvad andmelaos.
- säilitada ajaloolist andmestikku, eriti olukordades, kus info kustub ajapikku algallikatest.
- andmete pärimist optimiseerida: erinevalt rakenduste andmebaasidest, mis on optimeeritud andmete sisestamiseks, on andmeladu optimeeritud andmete pärimiseks. Andmeid saab struktureerida või koondada, et muuta nende pärimine võimalikult efektiivseks.
- integreerida ja ristkasutada mitmesuguseid algallikaid, luues ühtse andmebaasi. See võib tähendada ühe ettevõtte eri infosüsteemide sidumist (müük, ladu, finants, tootmine, tööajad jne). Samuti võib see tähendada kontserni tasemel nt müügi koondvaate jaoks grupi ettevõtete algallikatest andmete kokku integreerimist või siis avalike andmete kasutamist ettevõtte näitajates.
- luua analüütilisi äriülevaateid, mis on kohandatud organisatsiooni vajadustele ja harjumustele.
- detailsemat aruandlust: võrreldes algallikatega pakub andmeladu võimalust luua detailsemaid aruandeid, mis on olulised otsuste tegemisel.
Milleks kasutatakse relatsioonilist, milleks mitterelatsioonilist andmebaasi?
Valdavalt on infosüsteemid seotud relatsiooniliste andmebaasidega, samuti on analüütika-lahenduste algallikateks enamasti relatsioonilised andmebaasid nagu MS SQL Server, Oracle Database, PostgreSQL, MySQL, MariaDB jne.
Relatsioonilised andmebaasid on struktureeritud tabelite kujul, mis võimaldavad andmeid tõhusalt korraldada ja hallata, luues seeläbi tugeva aluse keerukatele päringutele ja andmeanalüüsile.
Mõnikord aga tekib vajadus säilitada teatud tüüpi andmeid, mida on optimaalsem hoida mitterelatsioonilistes andmebaasides. Intelex Insight kasutab nt logifaile ning masinõppe ja tehisintellekti (AI) lahenduste jaoks dokumendi- või pildifaile.
Erinevalt relatsioonilistest andmebaasidest, mis salvestavad andmeid rangelt määratletud tabelites, võimaldavad mitterelatsioonilised andmebaasid salvestada andmeid paindlikumal viisil. Seal andmete hoidmine on sageli kuluefektiivsem, eriti suurte andmekogumite puhul.
Mida tähendab andmebaasi normaliseerimine vs denormaliseerimine?
Normaliseerimise eesmärk on vähendada andmete kordusi, et tagada süsteemi tõhusus andmete sisestamise ja uuendamise protsessides. Vähendades üleliigsete väärtuste esinemist tabelites, paraneb andmebaasi haldamise kvaliteet. Infosüsteemides peetakse andmebaasi tavaliselt normaliseerituks, kui see vastab kolmanda taseme (3NF) nõuetele.
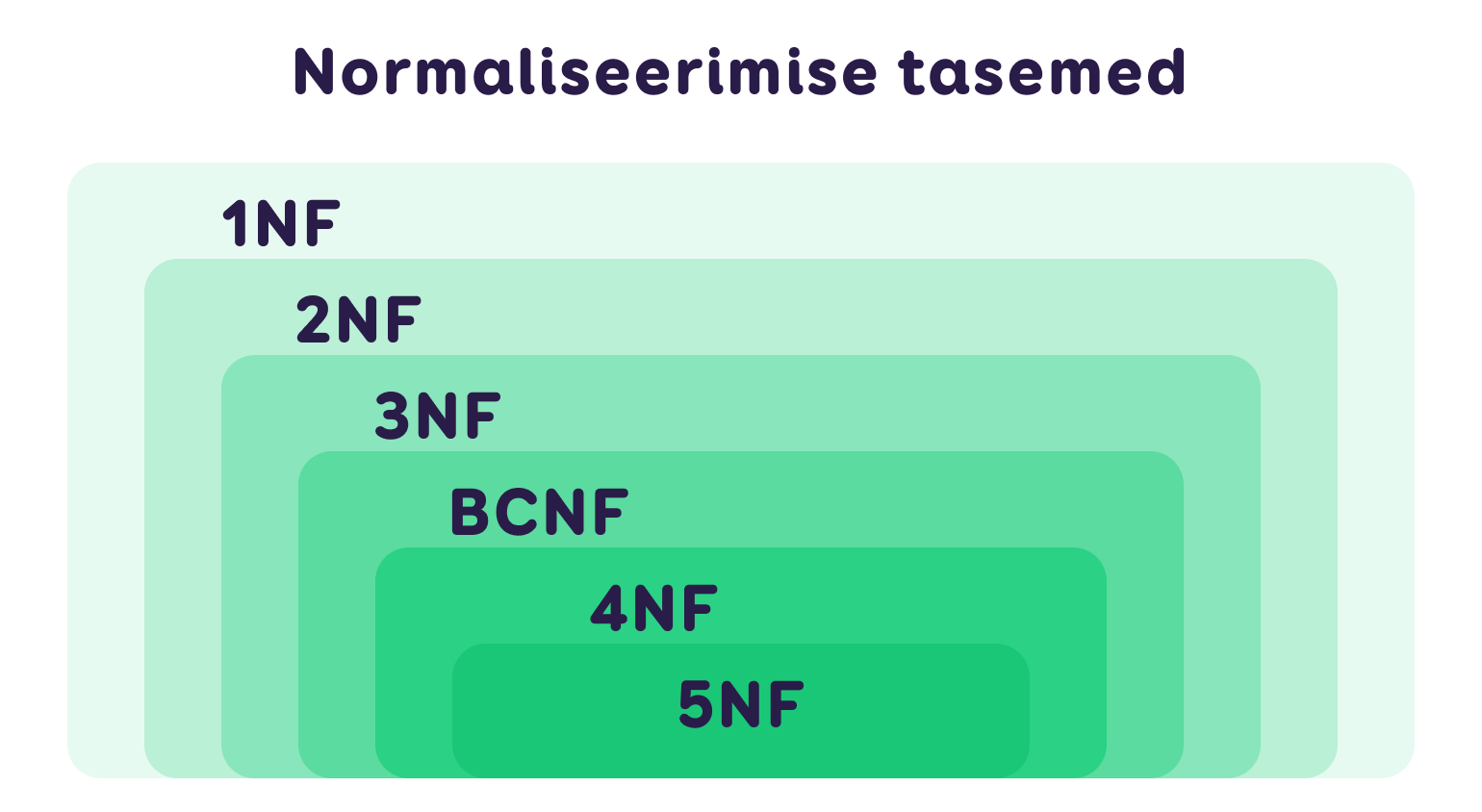
Denormaliseerimine keskendub tabelite vaheliste seoste vähendamisele, et optimeerida andmete lugemist. Üleliigsed seosed võivad andmebaasi päringute töötlemist aeglustada, seega denormaliseerimine aitab parandada päringute jõudlust, muutes andmebaasi päringutele kiiremini reageerivaks.
Dimensionaalne struktuur
Andmete struktureerimine äriliste protsesside ja ühiste dimensioonide (mille lõikes aruandlust vaadatakse) järgi pakub intuitiivset vaadet andmetele ning võimaldab ärikasutajatel lihtsamini andmetes orienteeruda.
Sellist ülesehitust nimetatakse ka Bus Matrix või Star Schema. Selles on andmed jaotatud viisil, mis toob esile nende seosed ja mustrid. Meetod on tõestanud oma tõhusust aruandluse esitamisel.

Järgnev joonis illustreerib ühe mudeli sama skeemi teisel kujul:
Struktureeritud andmeait tagab andmete hallatavuse ja turvalisuse
Struktureeritud lähenemine andmete haldamisele andmeaidas tagab mitte ainult andmete parema hallatavuse, vaid ka nende turvalisuse. Soovitatav on jaotada andmed kihtidesse, mis võimaldab eraldada eri tüüpi andmed ning hallata ligipääsu neile vastavalt vajadusele.
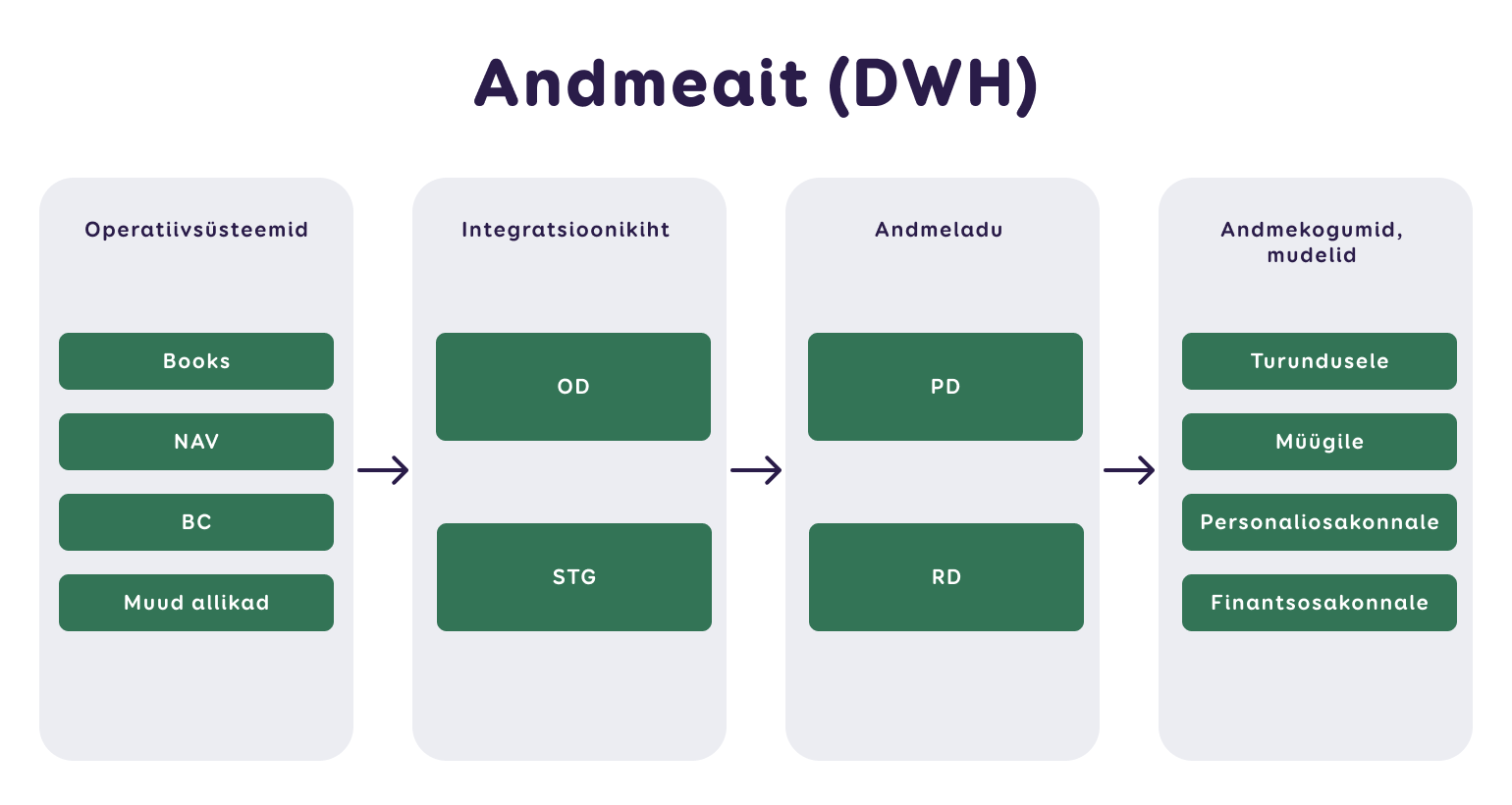
Teoorias eristatakse järgmisi kihte:
- Staging (STG) – see kiht on mõeldud enamasti ajutiseks andmete hoiustamiseks.
- Operational (OD) – siin asuvad töötlemata ehk toorandmed, mis on otse andmeallikatest laaditud ning ootavad edasist töötlemist.
- Processed (PD) – selles kihis on andmed viidud lähemale dimensionaalsele struktuurile ja on ümber töötatud selliselt, et need toetavad analüütikat ja päringuid. Sageli on see kiht üles ehitatud vaadetena, kui füüsilisi tabeleid pole vajalik luua.
- Report (RD) – aruandluskiht sisaldab raporteid ning spetsiifilisi tabeleid või vaateid, mis on seotud kindlate äriprobleemide lahendustega. Paljud organisatsioonid paigutavad oma andmemudelid just sellesse kihti.
- Data access layer (DAL) – see on andmeaida väline kiht, kus hoitakse raporteid ja analüüse.
Aeg-ajalt pannakse STG+OD või PD+RD kokku, see sõltub organisatsiooni vajadustest ja andmearhitektuuri keerukusest.
Järgnev joonis on taas üks illustratsioon, kuidas algandmetest kujundatakse spetsiifilised andmevakad või semantilised mudelid. Alustades algallikatest, laetakse andmed esmalt toorandmete kihti (STG, OD), mille järel edasi andmeid töödeldakse andmeaidas (PD, RD).
Seejärel luuakse spetsiifilised valdkonna andmekogumid (data marts) ja semantilised mudelid (datasets), mis on mõeldud lõppkasutajatele.
Metaandmete (metadata) tähtsus
Metaandmed on dokumenteeritud teave, mis annab ülevaate andmeaida arhitektuurist, andmetest ning nendega seotud loogikast ja protsessidest. Igal organisatsioonil peaks olema täielik kirjeldus oma andmevarude kohta, sh tabelite loetelu, andmete allikad, nende kasutuskohad jm.
Eristatakse kolme tüüpi metaandmeid:
- tehnilised metaandmed – need selgitavad andmeaida või BI süsteemi tehnilisi üksikasju, sh töötlemisprotsesse.
- ärilised metaandmed – need kirjeldavad andmeaida sisu äriterminoloogias, sh saadaolevate andmete olemasolu, nende päritolu, tähendust ja seotust teiste andmetega.
- protsessi metaandmed – kirjeldavad andmeaida tegevuste töötulemusi, nt andmete värskendamise protseduure, ajakava ja sagedust. Laadimisprotsessis on soovituslik salvestada logisid, mis dokumenteerivad öiste laadimiste edukust ja nt ka andmekirjete arvu.
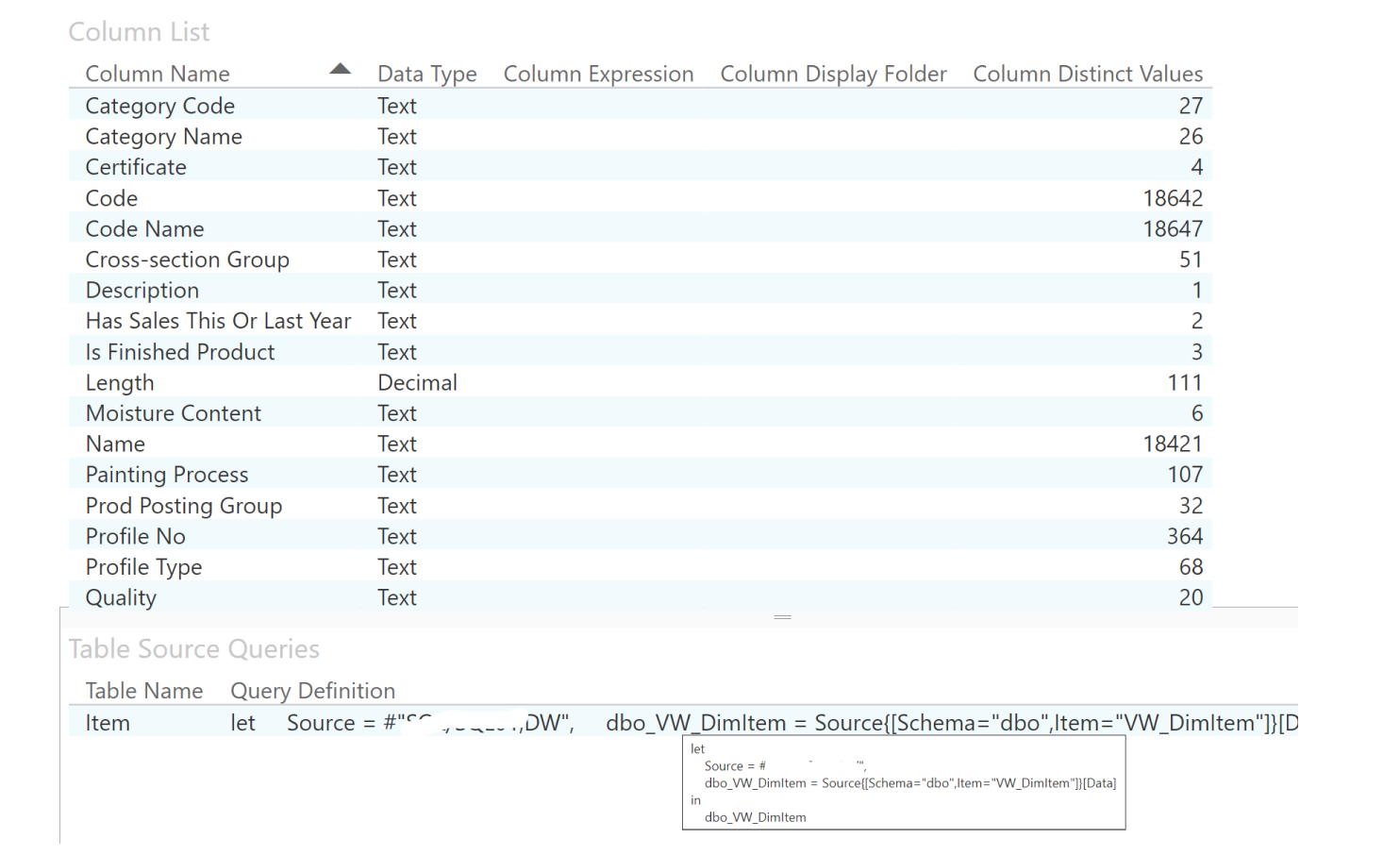
Näide ärilistest metaandmetest (metadata´st): kõige vasakpoolsemas veerus on loetletud tunnused ehk andmeväljad, mis toote dimensioonis on saadaval ning võimalik on näha iga tunnuse formaati ja unikaalsete väärtuste arvu.
Noolega osutamisel ilmuv äriline metaandmete osa annab teavet selle andmestiku allika kohta - näiteks antud juhul pärinevad andmed konkreetsest SQL-andmeaida vaatest.
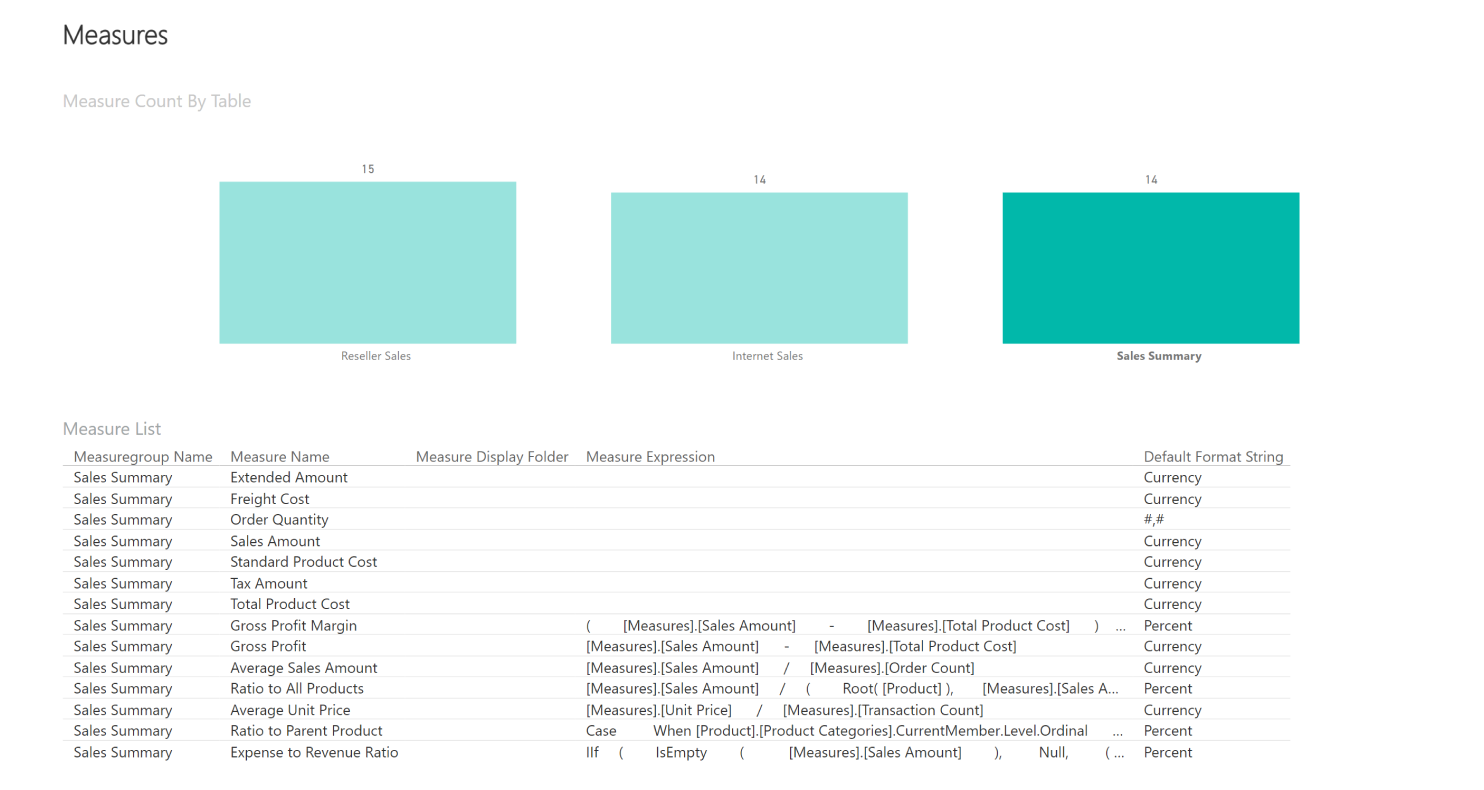
Lisaks on kasutajatele oluline teada, millised mõõdikud on tabelites esindatud ja milliseid valemeid on andmete analüüsimisel kasutatud. Läbipaistvuse ja mõistmise tagamiseks pakub Intelex Insight oma klientidele raportite kõrval juurdepääsu ka sellisele metaandmete infole.
Andmeaida/andmelao (DWH) arendamise põhimõtted
Andmeaida arendamisel tuleb arvestada mitmete oluliste aspektidega. Järgnevalt toome välja seitse olulisemat põhimõtet, mida Intelex Insight oma projektides järgib ja millega soovitame arvestada iga organisatsiooni andmeaida arendamisel:
- ühtne terminoloogia – projekti alguses sõlmime kokkulepped tellijaga ja tiimi sees, et määratleda terminid ja mõisted, mida projektis kasutatakse. Nii on kõigil osapooltel ühine arusaam ja dokumenteeritud terminoloogia aitab säilitada järjepidevust, isegi kui tiimi koosseis muutub.
- keelevalik – lepime tellijaga kokku, millises keeles andmeaita ja selle väljundeid (näiteks aruandeid) ning töö tulemeid esitame.
- skeemide kasutamine – visualiseerimiseks kasutame skeeme ja diagramme, mis aitavad paremini mõista andmestruktuure ja nende vahelisi seoseid.
- andmete laadimine – andmete laadimisel on oluline jälgida laadimise aega ja dokumenteerida viited algallikatele. OriginID lahendus võib siin abiks olla, lihtsustades andmete päritolu jälgimist.
- konfidentsiaalsed andmed – turvalisuse tagamiseks ja tundlike andmete käsitlemiseks lepime tellijaga kokku, kuidas andmeaita edasi arendatakse ja kes millistele andmetele ligi pääseb.
- andmete värskendamine – arvestada tuleb, et andmete liigutamine võtab aega. Näiteks raamatupidamiskannete puhul (kus raamatupidaja võib muuta ainult viimase majandusaasta andmeid) ja müügiandmete puhul (kus saavad muutuda vaid viimase kuu andmed) ei ole mõtet varasemaid andmeid uuendada. Kui kirjel on muutumise info olemas, saab värskendust teha selle järgi.
- andmete täpsuse kontroll – see on oluline igas andmete laadimise ja BI projekti etapis. Andmete kontrollimine tagab andmekvaliteedi ja usaldusväärsuse.
Modelleerimine (modelling) andmetöötluses
Modelleerimine tundub olevat natuke alahinnatud tähtsusega osa andmeanalüütikas. Semantilise mudeli üks eesmärke on anda ärikasutajale arusaadav vaade andmetele selliselt, et kui valmistehtud aruandest jääb väheks, siis saab kasutaja ise aruannet muuta ja täiendada või hoopis uue aruande koostada (see ei ole keeruline).
Andmemudelite eelis on see, et üldjuhul on need oma mootori poolt hästi optimeeritud päringuteks. Sõltuvalt töövahenditest kasutatakse selleks erinevaid meetodeid - näiteks kasutab MS Power BI oma tabulaarses mudelis VertiPaq Engine'i, mis pakib andmed efektiivselt andmekorduste arvelt.
Samas peab mudeli loomisel järgima ka arendaja parimaid praktikaid ning oluline on keskenduda ainult nendele andmetele, mis on lõppkasutaja jaoks vajalikud. Liigne info võib mudelisse tekitada pika aja peale nii palju müra, et mudel muutub lõpuks kasutamatuks.
MS ärianalüütika tööriistad
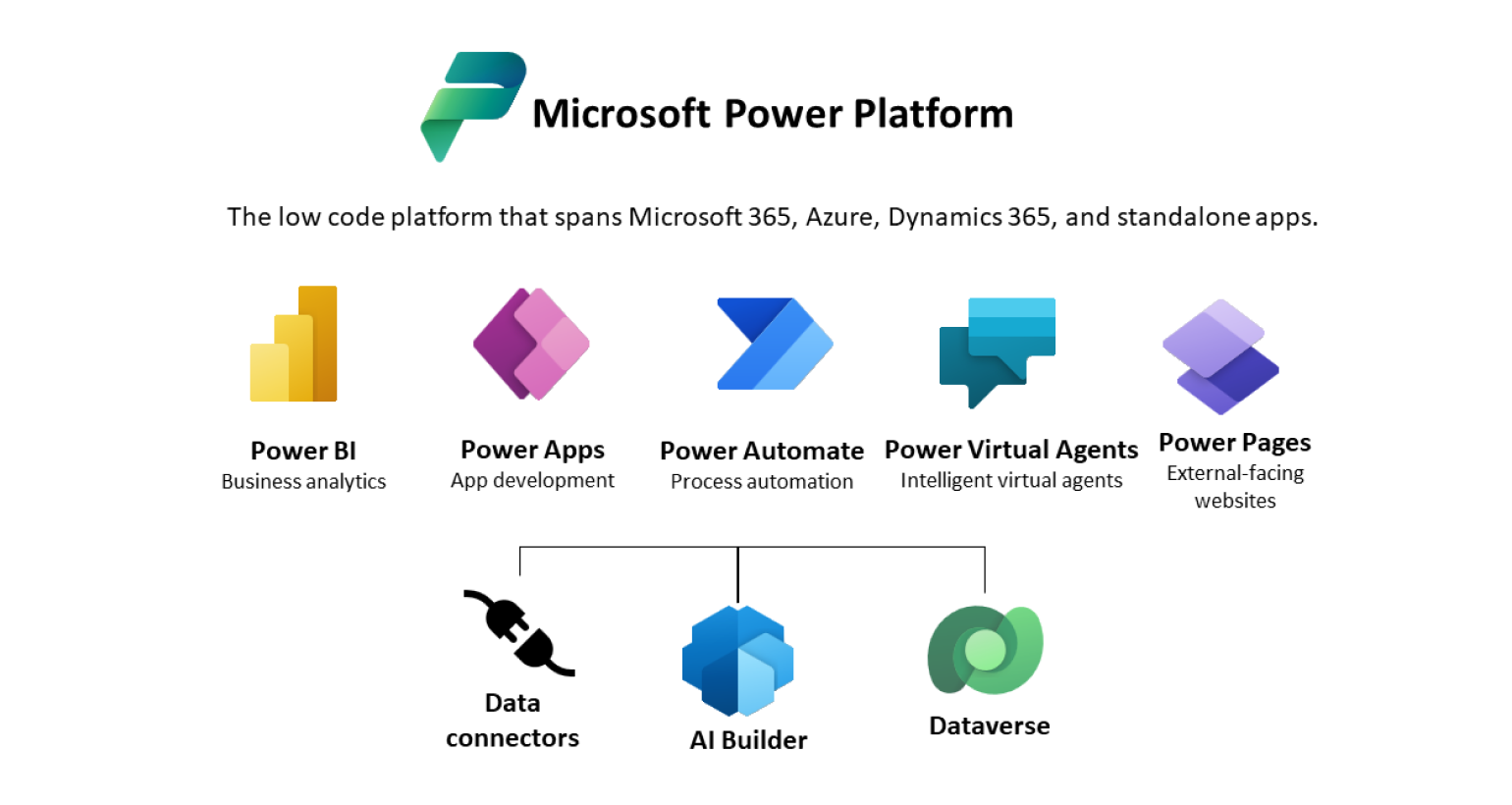
Intelex Insight kasutab Microsoft´i tööriistade portfelli andmepõhiste aruannete ja andmekaeve projektide elluviimiseks. Anname põgusa ülevaate peamistest tööriistadest ja nende kasutusaladest:
- Power BI – see on aruandlustööriist, mida saab kasutada nii arvutis rakendusena kui ka veebipõhiselt. Power BI toetab andmete integreerimist erinevatest allikatest, nagu Excel, SQL andmebaasid või otseühendused teiste andmebaasidega. Lisaks võimaldab see töötada arendaja poolt loodud mudelitel. Võid julgelt Power BI kasutamisega ka ise alustada ja näiteks mõnest isiklikust Exceli tabelist andmed sisse lugeda. See on üsna lihtne. Vaata siit juhiseid.
- Power Apps – kui on vajadus andmeid sisestada, siis Power Apps pakub lihtsat ja kiirelt loodavat lahendust. Selle abil saad arendada veebirakendusi, mis on otse ühendatud andmeaidaga, võimaldades kasutajatel andmeid operatiivselt sisestada ja hallata.
- Power Automate – veebipõhine tööriist andmete automatiseeritud protsessideks.
- Power Virtual Agents – juturobotid, mis on loodud lihtsustama suhtlust ja automaatset vastuste genereerimist MS Teams’is.
- Power Pages – tööriist veebiliideste loomiseks, mis võimaldab luua veebilehti Power BI aruannete kuvamiseks ja interaktiivsete andmeanalüüsi vahendite pakkumiseks.
Kokkuvõtteks
Andmeanalüütika täidab äriotsuste tegemisel olulist rolli. Efektiivsed BI lahendused ja nende arendamine põhinevad selgetel standarditel ja parimatel praktikatel, kasutades sobivaid aruandluse ja analüüsi tööriistu.
Loodame, et leidsid meie artiklist kasulikku infot, mis aitab sul andmeanalüütika keerukas maailmas paremini navigeerida ja seda edukalt oma organisatsiooni eesmärkide saavutamiseks rakendada.





